TL;DR: I created Anki collection by parsing koreanclass101.com web site content with python 3, extracted work-cards
with images and pronunciation sounds
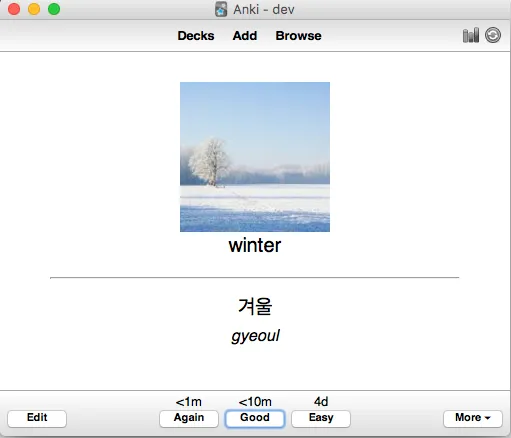
Anki is a cool program, which makes easy to memorize anything.
It’s free (but not for iOS) and cross-platform. I use it with foreign languages, to commit to memory large amounts of
words, but the main problem is to find good collection, that fits my needs. I want the collection to have an image
describing word, and a sound from native-speaker. Most shared free collections from
anki decks site are not as perfect.
The good way to create one is to find site for students learning the language, and write a program which will go
through pages, collect data and save the deck. So, we need to know, how Anki collection is structured, and how to
extract information from the web page. Luckily Anki is open source and web sites usually have clear HTML structure,
so it is not as difficult as it sounds.
Anki collection is a file with .apkg extension. It is just zip archive contains media files (they do not have
extensions and their names are just numbers), and two files: media (contain media files index), and collection.anki2
which is an SQLite database file.
I will be using python 3 as it really good for such problems. So the first step is to create some folder (let its name
be data) and create SQlite database file
1 | import os |
Each time script run it will destroy the folder and create it again. I created a number of constants and simple class
to work with database
1 | ANKI_TABLE_CARDS = """CREATE TABLE cards ( |
Lets take a look on koreanclass101 web site, which we are using as a target.
Every day it provides a free korean word, with url like
https://www.koreanclass101.com/korean-phrases/10302017?meaning
We can see there is a date in the URL (10302017 – October 30th, 2017), and korean word, sound, image and translation
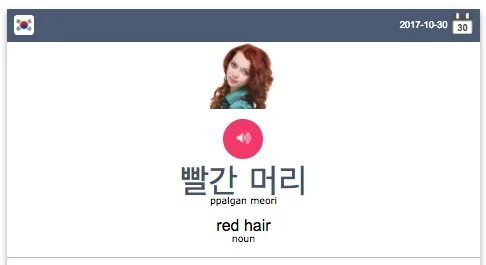
But when we look closer, we see there is no such content in HTML. Actually there is JS code, that makes POST request on
URL /widgets/wotd/large.php with form data (language=Korean&date=2017–10–30). The answer is the piece of HTML displayed
above, so we can just make POST request for each date and parse the HTML we need.
We will start from June 10’th of 2013 (all cards before have invalid images). Simple python date iterator will be as following:
1 | from datetime import datetime, timedelta |
For each date we will download HTML using POST request
1 | def make_post_data(date): |
Lets create a plain python object with public fields to contain one card information and few help methods
1 | class Card(object): |
The parser collects data from HTML and fill the Card object fields. We will be using html.parser python package.
To distinguish numerous of <div> elements, we’ll be using class variable __div_classes that collects path in DOM-tree
of class names for each div. So, when entering <div> element we push its class name, and when exit — remove it from
the list.
1 | from html.parser import HTMLParser |
Saving card to database is quite easy. All the cards have two variants (one show english word and asks about korean
translation, other shows korean word and wait ith translation into english). We have to add 2 rows into table ‘card’
and one into table ‘notes’. Card fields go to column ‘flds’ (string) of table ‘notes’, separated by “\x1f” char.
They must be in predefined order, described in table ‘col’ which we created earler in field ‘model’ which contains
JSON like that:
1 | "flds": [ |
All the new rows must have unique id, so we will save the id of first entry and increment it manually. Also we save
part of speech of the word (noun, verb, etc…) to field tags.
So, here two new methods in class AnkiDB
1 | def __add_node(self, card): |
For each card we download image and sound files. Their names must be just numbers, and for each file we have to add its
index to file named ‘media’ which contains JSON hash object like
1 | { |
So, lets create a class registers all the media files
1 | class MediaRegistrar(object): |
And download media files
1 | def download_media_files(card, media_registrar): |
The final step is to zip each file in data folder into one archive. This can also be done with python
1 | z = ZipFile("koreanclass101.apkg", "w") |
After successfull run (about 15 minutes) we have the job done
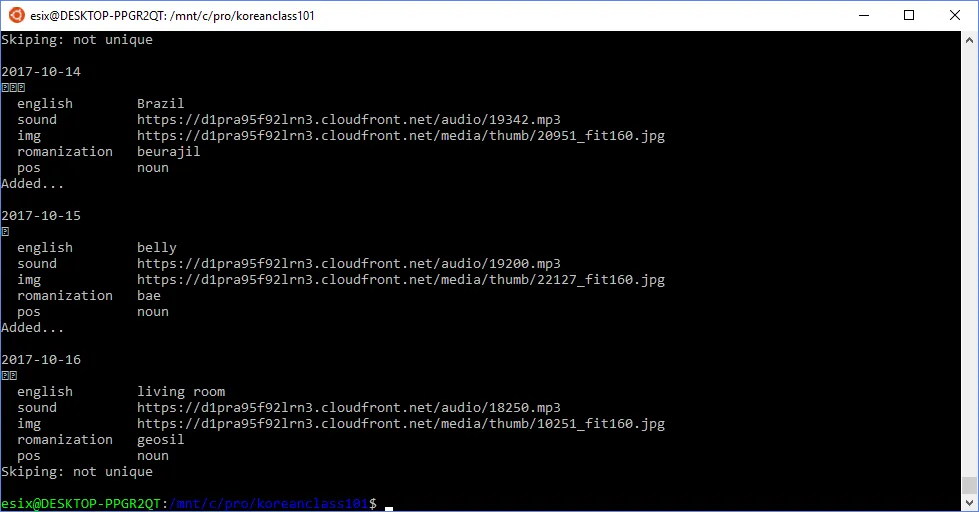
We have collected 613 unique words (total 1226 cards), so it can be a good start of learning Korean
Full source code:
Download ready deck at: